Overview
forestBalance estimates average treatment effects (ATE)
in observational studies by combining multivariate random forests with
kernel energy balancing. The key idea is:
- Fit a random forest that jointly predicts treatment and outcome from covariates, so that the tree structure captures confounding.
- Use the forest’s leaf co-membership to define a similarity kernel.
- Obtain balancing weights via a closed-form kernel energy distance solution.
Because the kernel reflects the nonlinear relationships between covariates, treatment, and outcome, the resulting weights can balance complex confounding structure that linear methods may miss.
The method is described in:
De, S. and Huling, J.D. (2025). Data adaptive covariate balancing for causal effect estimation for high dimensional data. arXiv:2512.18069.
Simulating data
simulate_data() generates observational data with
nonlinear confounding. The propensity score depends on
through a Beta density, and the outcome depends nonlinearly on
,
,
and
:
set.seed(123)
dat <- simulate_data(n = 800, p = 10, ate = 0)
c("True ATE" = dat$ate,
"Naive ATE" = round(mean(dat$Y[dat$A == 1]) - mean(dat$Y[dat$A == 0]), 4))
#> True ATE Naive ATE
#> 0.0000 1.7054The naive difference-in-means is badly biased because of confounding.
Estimating the ATE
Forest balance
fit_fb <- forest_balance(dat$X, dat$A, dat$Y, num.trees = 1000)
fit_fb
#> Forest Kernel Energy Balancing (cross-fitted)
#> --------------------------------------------------
#> n = 800 (n_treated = 284, n_control = 516)
#> Trees: 1000
#> Cross-fitting: 2 folds
#> Solver: direct
#> ATE estimate: 0.0741
#> Fold ATEs: 0.1184, 0.0298
#> ESS: treated = 190/284 (67%) control = 386/516 (75%)
#> --------------------------------------------------
#> Use summary() for covariate balance details.Entropy balancing (WeightIt)
Entropy balancing finds weights that exactly balance covariate means between treated and control groups:
df <- data.frame(A = dat$A, dat$X)
fit_ebal <- weightit(A ~ ., data = df, method = "ebal")
ate_ebal <- weighted.mean(dat$Y[dat$A == 1], fit_ebal$weights[dat$A == 1]) -
weighted.mean(dat$Y[dat$A == 0], fit_ebal$weights[dat$A == 0])Energy balancing (WeightIt)
Energy balancing minimizes the energy distance between the weighted treated and control covariate distributions:
fit_energy <- weightit(A ~ ., data = df, method = "energy")
ate_energy <- weighted.mean(dat$Y[dat$A == 1], fit_energy$weights[dat$A == 1]) -
weighted.mean(dat$Y[dat$A == 0], fit_energy$weights[dat$A == 0])Covariate balance
summary() shows the full balance comparison. Let’s also
check balance on nonlinear transformations of the covariates, since the
confounding operates through the Beta density:
X <- dat$X
X.nl <- cbind(
X[, 1]^2, X[, 2]^2, X[, 5]^2,
X[, 1] * X[, 2], X[, 1] * X[, 5],
dbeta(X[, 1], 2, 4), dbeta(X[, 5], 2, 4)
)
colnames(X.nl) <- c("X1^2", "X2^2", "X5^2", "X1*X2", "X1*X5",
"Beta(X1)", "Beta(X5)")
summary(fit_fb, X.trans = X.nl)
#> Forest Kernel Energy Balancing
#> ============================================================
#> n = 800 (n_treated = 284, n_control = 516)
#> Trees: 1000
#> Solver: CG (kernel not materialized)
#>
#> ATE estimate: 0.0741
#> ============================================================
#>
#> Covariate Balance (|SMD|)
#> ------------------------------------------------------------
#> Covariate Unweighted Weighted
#> ---------- ------------ ------------
#> X1 0.2467 * 0.0082
#> X2 0.0052 0.0178
#> X3 0.0690 0.0167
#> X4 0.0096 0.0036
#> X5 0.0382 0.0286
#> X6 0.0633 0.0236
#> X7 0.0354 0.0375
#> X8 0.0040 0.0236
#> X9 0.1140 * 0.0083
#> X10 0.1740 * 0.1085 *
#> ---------- ------------ ------------
#> Max |SMD| 0.2467 0.1085
#> (* indicates |SMD| > 0.10)
#>
#> Transformed Covariate Balance (|SMD|)
#> ------------------------------------------------------------
#> Transform Unweighted Weighted
#> ---------- ------------ ------------
#> X1^2 0.1769 * 0.0440
#> X2^2 0.0125 0.0061
#> X5^2 0.0453 0.0548
#> X1*X2 0.0397 0.0284
#> X1*X5 0.0407 0.0009
#> Beta(X1) 0.7025 * 0.0258
#> Beta(X5) 0.1256 * 0.0041
#> ---------- ------------ ------------
#> Max |SMD| 0.7025 0.0548
#>
#> Effective Sample Size
#> ------------------------------------------------------------
#> Treated: 190 / 284 (67%)
#> Control: 386 / 516 (75%)
#>
#> Energy Distance
#> ------------------------------------------------------------
#> Unweighted: 0.0397
#> Weighted: 0.0173
#> ============================================================We can use compute_balance() to compare all methods on
the same terms:
bal_fb <- compute_balance(dat$X, dat$A, fit_fb$weights, X.trans = X.nl)
bal_ebal <- compute_balance(dat$X, dat$A, fit_ebal$weights, X.trans = X.nl)
bal_energy <- compute_balance(dat$X, dat$A, fit_energy$weights, X.trans = X.nl)
bal_unwtd <- compute_balance(dat$X, dat$A, rep(1, dat$n), X.trans = X.nl)| Method | Max SMD (linear) | Max SMD (nonlinear) | ESS treated | ESS control |
|---|---|---|---|---|
| Unweighted | 0.2467 | 0.7025 | 100% | 100% |
| Entropy balancing | 0.0000 | 0.6375 | 94% | 98% |
| Energy balancing | 0.0123 | 0.5748 | 84% | 87% |
| Forest balance | 0.1085 | 0.0548 | 67% | 75% |
All three weighting methods reduce the linear covariate imbalance. Both energy balancing the forest balance approach also reduce imbalance on nonlinear functions of the covariates, as they both aim to balance the joint distributions of covariates, however, forest balancing over-emphasizes full distributional balance of confounders specifically rather than all possible covariates.
Simulation study
A simulation study with 100 replications at two sample sizes ( and ) demonstrates how the methods compare and how performance changes with :
run_sim <- function(n, nreps = 50, num.trees = 500, seed = 1) {
set.seed(seed)
methods <- c("Naive", "Entropy", "Energy", "Forest")
results <- matrix(NA, nreps, length(methods), dimnames = list(NULL, methods))
for (r in seq_len(nreps)) {
dat <- simulate_data(n = n, p = 10, ate = 0)
df <- data.frame(A = dat$A, dat$X)
fit_fb <- forest_balance(dat$X, dat$A, dat$Y, num.trees = num.trees)
w_ebal <- tryCatch(weightit(A ~ ., data = df, method = "ebal")$weights,
error = function(e) rep(1, dat$n))
w_energy <- tryCatch(weightit(A ~ ., data = df, method = "energy")$weights,
error = function(e) rep(1, dat$n))
results[r, "Naive"] <- mean(dat$Y[dat$A == 1]) - mean(dat$Y[dat$A == 0])
results[r, "Entropy"] <- weighted.mean(dat$Y[dat$A == 1], w_ebal[dat$A == 1]) -
weighted.mean(dat$Y[dat$A == 0], w_ebal[dat$A == 0])
results[r, "Energy"] <- weighted.mean(dat$Y[dat$A == 1], w_energy[dat$A == 1]) -
weighted.mean(dat$Y[dat$A == 0], w_energy[dat$A == 0])
results[r, "Forest"] <- fit_fb$ate
}
results
}
res_500 <- run_sim(n = 500, seed = 1)
res_1000 <- run_sim(n = 1000, seed = 1)| n | Method | Bias | SD | RMSE |
|---|---|---|---|---|
| 500 | Naive | 1.2495 | 0.3097 | 1.2873 |
| 500 | Entropy | 0.9682 | 0.2222 | 0.9934 |
| 500 | Energy | 0.8459 | 0.2222 | 0.8746 |
| 500 | Forest | 0.0736 | 0.1585 | 0.1748 |
| 1000 | Naive | 1.3102 | 0.2441 | 1.3328 |
| 1000 | Entropy | 0.9841 | 0.1554 | 0.9963 |
| 1000 | Energy | 0.8107 | 0.1478 | 0.8240 |
| 1000 | Forest | 0.0524 | 0.0969 | 0.1101 |
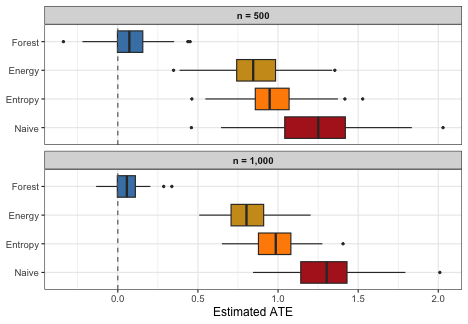
All weighting methods improve over the naive estimator. At , entropy balancing (which only targets linear covariate means) retains substantial bias, while energy balancing and forest balance both reduce bias more effectively. At , all methods improve, but forest balance continues to show the lowest bias and competitive RMSE, reflecting the advantage of its confounding-targeted kernel.
Step-by-step interface
For more control, the pipeline can be run in stages:
library(grf)
dat <- simulate_data(n = 500, p = 10)
# 1. Fit the joint forest
forest <- multi_regression_forest(dat$X, scale(cbind(dat$A, dat$Y)),
num.trees = 500)
# 2. Extract leaf node matrix (n x B)
leaf_mat <- get_leaf_node_matrix(forest, dat$X)
dim(leaf_mat)
#> [1] 500 500
# 3. Build sparse proximity kernel
K <- leaf_node_kernel(leaf_mat)
c("kernel % nonzero" = round(100 * length(K@x) / prod(dim(K)), 1))
#> kernel % nonzero
#> 29.7
# 4. Compute balancing weights
bal <- kernel_balance(dat$A, K)
# 5. Estimate ATE
weighted.mean(dat$Y[dat$A == 1], bal$weights[dat$A == 1]) -
weighted.mean(dat$Y[dat$A == 0], bal$weights[dat$A == 0])
#> [1] 0.2321743